
Reading an Argo CTD cycle data#
The first cycle#

An Argo cycle starts with a descent towards deep water, usually from the surface, and ends after the next programmed ascent to the surface (see the figure). During the surface interval, data transmission typically occurs but it is not a requirement for a cycle to have occurred. If it occurs, the cycle ends after the full surface interval has been completed.
Nowadays Argo floats can measure different parameters, however, we will focus on what is called the Argo core mission, this is observations of temperature, salinity and pressure down to 2000 meters of depth. The measurements are performed during ascent, occasionally during descent, and subsurface measurements during parking are sometimes performed.
Each cycle of a float has a unique number, increased by one after each ascent to the surface or shallow water. Float cycle numbers usually start at 1. The next cycles are increasing numbers (e.g. 2, 3,…N). Some floats report a cycle 0, called launch cycle, which is shorter than the regular cycles. The cycle time is therefore regular only for later profiles and may be variable if the float is reprogrammed after its deployment.
For those floats with cycle 0, if there is an initial descend profile, it would be on cycle 0.
First, import libraries.
import numpy as np
import xarray as xr
import netCDF4
from matplotlib import pyplot as plt
%matplotlib inline
cy1 = xr.open_dataset('../../Data/6901254/profiles/R6901254_001.nc')
Printing the object gives you summary information.
cy1
<xarray.Dataset>
Dimensions: (N_PROF: 2, N_PARAM: 3, N_LEVELS: 97, N_HISTORY: 3, N_CALIB: 1)
Dimensions without coordinates: N_PROF, N_PARAM, N_LEVELS, N_HISTORY, N_CALIB
Data variables: (12/64)
DATA_TYPE object b'Argo profile '
FORMAT_VERSION object b'3.1 '
HANDBOOK_VERSION object b'1.2 '
REFERENCE_DATE_TIME object b'19500101000000'
DATE_CREATION object b'20190115112518'
DATE_UPDATE object b'20190115112524'
... ...
HISTORY_QCTEST (N_HISTORY, N_PROF) object b' ...
PARAMETER (N_PROF, N_CALIB, N_PARAM) object b'PRES ...
SCIENTIFIC_CALIB_EQUATION (N_PROF, N_CALIB, N_PARAM) object b' ...
SCIENTIFIC_CALIB_COEFFICIENT (N_PROF, N_CALIB, N_PARAM) object b' ...
SCIENTIFIC_CALIB_COMMENT (N_PROF, N_CALIB, N_PARAM) object b' ...
SCIENTIFIC_CALIB_DATE (N_PROF, N_CALIB, N_PARAM) object b' ...
Attributes:
title: Argo float vertical profile
institution: CORIOLIS
source: Argo float
history: 2019-01-15T11:25:18Z creation; 2019-01-15T11:25:24Z...
references: http://www.argodatamgt.org/Documentation
user_manual_version: 3.1
Conventions: Argo-3.1 CF-1.6
featureType: trajectoryProfile
decoder_version: CODA_027d- N_PROF: 2
- N_PARAM: 3
- N_LEVELS: 97
- N_HISTORY: 3
- N_CALIB: 1
- DATA_TYPE()object...
- long_name :
- Data type
- conventions :
- Argo reference table 1
array(b'Argo profile ', dtype=object)
- FORMAT_VERSION()object...
- long_name :
- File format version
array(b'3.1 ', dtype=object)
- HANDBOOK_VERSION()object...
- long_name :
- Data handbook version
array(b'1.2 ', dtype=object)
- REFERENCE_DATE_TIME()object...
- long_name :
- Date of reference for Julian days
- conventions :
- YYYYMMDDHHMISS
array(b'19500101000000', dtype=object)
- DATE_CREATION()object...
- long_name :
- Date of file creation
- conventions :
- YYYYMMDDHHMISS
array(b'20190115112518', dtype=object)
- DATE_UPDATE()object...
- long_name :
- Date of update of this file
- conventions :
- YYYYMMDDHHMISS
array(b'20190115112524', dtype=object)
- PLATFORM_NUMBER(N_PROF)object...
- long_name :
- Float unique identifier
- conventions :
- WMO float identifier : A9IIIII
array([b'6901254 ', b'6901254 '], dtype=object)
- PROJECT_NAME(N_PROF)object...
- long_name :
- Name of the project
array([b'ARGO SPAIN ', b'ARGO SPAIN '], dtype=object) - PI_NAME(N_PROF)object...
- long_name :
- Name of the principal investigator
array([b'Pedro Velez ', b'Pedro Velez '], dtype=object) - STATION_PARAMETERS(N_PROF, N_PARAM)object...
- long_name :
- List of available parameters for the station
- conventions :
- Argo reference table 3
array([[b'PRES ', b'TEMP ', b'PSAL '], [b'PRES ', b'TEMP ', b'PSAL ']], dtype=object) - CYCLE_NUMBER(N_PROF)float64...
- long_name :
- Float cycle number
- conventions :
- 0...N, 0 : launch cycle (if exists), 1 : first complete cycle
array([1., 1.])
- DIRECTION(N_PROF)object...
- long_name :
- Direction of the station profiles
- conventions :
- A: ascending profiles, D: descending profiles
array([b'A', b'A'], dtype=object)
- DATA_CENTRE(N_PROF)object...
- long_name :
- Data centre in charge of float data processing
- conventions :
- Argo reference table 4
array([b'IF', b'IF'], dtype=object)
- DC_REFERENCE(N_PROF)object...
- long_name :
- Station unique identifier in data centre
- conventions :
- Data centre convention
array([b' ', b' '], dtype=object) - DATA_STATE_INDICATOR(N_PROF)object...
- long_name :
- Degree of processing the data have passed through
- conventions :
- Argo reference table 6
array([b'2B ', b'2B '], dtype=object)
- DATA_MODE(N_PROF)object...
- long_name :
- Delayed mode or real time data
- conventions :
- R : real time; D : delayed mode; A : real time with adjustment
array([b'R', b'R'], dtype=object)
- PLATFORM_TYPE(N_PROF)object...
- long_name :
- Type of float
- conventions :
- Argo reference table 23
array([b'ARVOR ', b'ARVOR '], dtype=object) - FLOAT_SERIAL_NO(N_PROF)object...
- long_name :
- Serial number of the float
array([b'AL2500-17SP003 ', b'AL2500-17SP003 '], dtype=object) - FIRMWARE_VERSION(N_PROF)object...
- long_name :
- Instrument firmware version
array([b'n/a ', b'n/a '], dtype=object) - WMO_INST_TYPE(N_PROF)object...
- long_name :
- Coded instrument type
- conventions :
- Argo reference table 8
array([b'844 ', b'844 '], dtype=object)
- JULD(N_PROF)datetime64[ns]...
- long_name :
- Julian day (UTC) of the station relative to REFERENCE_DATE_TIME
- standard_name :
- time
- conventions :
- Relative julian days with decimal part (as parts of day)
- resolution :
- 0.0006944444444444445
- axis :
- T
- comment_on_resolution :
- JULD resolution is 1 minute, except when JULD = JULD_LOCATION or when JULD = JULD_FIRST_MESSAGE (TRAJ file variable); in that case, JULD resolution is 1 second
array(['2018-10-25T05:30:00.000000000', '2018-10-25T05:30:00.000000000'], dtype='datetime64[ns]') - JULD_QC(N_PROF)object...
- long_name :
- Quality on date and time
- conventions :
- Argo reference table 2
array([b'1', b'1'], dtype=object)
- JULD_LOCATION(N_PROF)datetime64[ns]...
- long_name :
- Julian day (UTC) of the location relative to REFERENCE_DATE_TIME
- conventions :
- Relative julian days with decimal part (as parts of day)
- resolution :
- 1.1574074074074073e-05
array(['2018-10-25T05:45:54.000002048', '2018-10-25T05:45:54.000002048'], dtype='datetime64[ns]') - LATITUDE(N_PROF)float64...
- long_name :
- Latitude of the station, best estimate
- standard_name :
- latitude
- units :
- degree_north
- valid_min :
- -90.0
- valid_max :
- 90.0
- axis :
- Y
array([29.182, 29.182])
- LONGITUDE(N_PROF)float64...
- long_name :
- Longitude of the station, best estimate
- standard_name :
- longitude
- units :
- degree_east
- valid_min :
- -180.0
- valid_max :
- 180.0
- axis :
- X
array([-15.429, -15.429])
- POSITION_QC(N_PROF)object...
- long_name :
- Quality on position (latitude and longitude)
- conventions :
- Argo reference table 2
array([b'1', b'1'], dtype=object)
- POSITIONING_SYSTEM(N_PROF)object...
- long_name :
- Positioning system
array([b'ARGOS ', b'ARGOS '], dtype=object)
- PROFILE_PRES_QC(N_PROF)object...
- long_name :
- Global quality flag of PRES profile
- conventions :
- Argo reference table 2a
array([b'A', b'A'], dtype=object)
- PROFILE_TEMP_QC(N_PROF)object...
- long_name :
- Global quality flag of TEMP profile
- conventions :
- Argo reference table 2a
array([b'A', b'C'], dtype=object)
- PROFILE_PSAL_QC(N_PROF)object...
- long_name :
- Global quality flag of PSAL profile
- conventions :
- Argo reference table 2a
array([b'A', b'F'], dtype=object)
- VERTICAL_SAMPLING_SCHEME(N_PROF)object...
- long_name :
- Vertical sampling scheme
- conventions :
- Argo reference table 16
array([b'Primary sampling: averaged [10 sec sampling, 25 dbar average from 2000 dbar to 200 dbar; 10 sec sampling, 10 dbar average from 200 dbar to 10 dbar; 10 sec sampling, 1 dbar average from 10 dbar to 5.5 dbar] ', b'Near-surface sampling: averaged, unpumped [10 sec sampling, 1 dbar average from 5.5 dbar to surface] '], dtype=object) - CONFIG_MISSION_NUMBER(N_PROF)float64...
- long_name :
- Unique number denoting the missions performed by the float
- conventions :
- 1...N, 1 : first complete mission
array([1., 1.])
- PRES(N_PROF, N_LEVELS)float32...
- long_name :
- Sea water pressure, equals 0 at sea-level
- standard_name :
- sea_water_pressure
- units :
- decibar
- valid_min :
- 0.0
- valid_max :
- 12000.0
- C_format :
- %7.1f
- FORTRAN_format :
- F7.1
- resolution :
- 1.0
- axis :
- Z
array([[6.000e+00, 7.000e+00, 8.000e+00, 9.000e+00, 1.000e+01, 1.500e+01, 2.500e+01, 3.600e+01, 4.500e+01, 5.500e+01, 6.600e+01, 7.600e+01, 8.600e+01, 9.600e+01, 1.050e+02, 1.150e+02, 1.250e+02, 1.350e+02, 1.460e+02, 1.550e+02, 1.650e+02, 1.750e+02, 1.850e+02, 1.950e+02, 2.130e+02, 2.380e+02, 2.630e+02, 2.880e+02, 3.130e+02, 3.380e+02, 3.630e+02, 3.880e+02, 4.140e+02, 4.380e+02, 4.630e+02, 4.880e+02, 5.130e+02, 5.380e+02, 5.630e+02, 5.880e+02, 6.130e+02, 6.380e+02, 6.630e+02, 6.880e+02, 7.130e+02, 7.380e+02, 7.630e+02, 7.880e+02, 8.130e+02, 8.380e+02, 8.630e+02, 8.880e+02, 9.130e+02, 9.380e+02, 9.630e+02, 9.880e+02, 1.013e+03, 1.038e+03, 1.063e+03, 1.088e+03, 1.113e+03, 1.138e+03, 1.163e+03, 1.188e+03, 1.213e+03, 1.238e+03, 1.263e+03, 1.288e+03, 1.313e+03, 1.338e+03, 1.363e+03, 1.388e+03, 1.414e+03, 1.438e+03, 1.463e+03, 1.488e+03, 1.513e+03, 1.538e+03, 1.564e+03, 1.588e+03, 1.613e+03, 1.638e+03, 1.663e+03, 1.688e+03, 1.713e+03, 1.738e+03, 1.763e+03, 1.788e+03, 1.813e+03, 1.838e+03, 1.863e+03, 1.888e+03, 1.913e+03, 1.938e+03, 1.963e+03, 1.988e+03, 2.011e+03], [0.000e+00, 1.000e+00, 2.000e+00, 3.000e+00, 4.000e+00, 5.000e+00, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan]], dtype=float32) - PRES_QC(N_PROF, N_LEVELS)object...
- long_name :
- quality flag
- conventions :
- Argo reference table 2
array([[b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1'], [b'1', b'1', b'1', b'1', b'1', b'1', nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan]], dtype=object) - PRES_ADJUSTED(N_PROF, N_LEVELS)float32...
- long_name :
- Sea water pressure, equals 0 at sea-level
- standard_name :
- sea_water_pressure
- units :
- decibar
- valid_min :
- 0.0
- valid_max :
- 12000.0
- C_format :
- %7.1f
- FORTRAN_format :
- F7.1
- resolution :
- 1.0
- axis :
- Z
array([[nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan], [nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan]], dtype=float32) - PRES_ADJUSTED_QC(N_PROF, N_LEVELS)object...
- long_name :
- quality flag
- conventions :
- Argo reference table 2
array([[nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan], [nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan]], dtype=object) - PRES_ADJUSTED_ERROR(N_PROF, N_LEVELS)float32...
- long_name :
- Contains the error on the adjusted values as determined by the delayed mode QC process
- units :
- decibar
- C_format :
- %7.1f
- FORTRAN_format :
- F7.1
- resolution :
- 1.0
array([[nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan], [nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan]], dtype=float32) - TEMP(N_PROF, N_LEVELS)float32...
- long_name :
- Sea temperature in-situ ITS-90 scale
- standard_name :
- sea_water_temperature
- units :
- degree_Celsius
- valid_min :
- -2.5
- valid_max :
- 40.0
- C_format :
- %9.3f
- FORTRAN_format :
- F9.3
- resolution :
- 0.001
array([[23.412, 23.412, 23.414, 23.412, 23.413, 23.41 , 23.398, 23.362, 21.52 , 19.551, 18.408, 17.947, 17.689, 17.378, 17.074, 17. , 16.869, 16.576, 16.334, 16.113, 15.882, 15.702, 15.486, 15.234, 14.892, 14.422, 14.024, 13.581, 13.244, 12.933, 12.75 , 12.526, 12.222, 11.994, 11.726, 11.396, 11.176, 10.982, 10.741, 10.528, 10.293, 10.098, 9.868, 9.731, 9.553, 9.394, 9.214, 9.099, 8.965, 8.795, 8.627, 8.502, 8.388, 8.374, 8.374, 8.366, 8.329, 8.241, 8.128, 8.089, 8.106, 8.091, 8.171, 8.175, 8.029, 7.794, 7.568, 7.41 , 7.244, 7.081, 6.958, 6.882, 6.69 , 6.64 , 6.538, 6.452, 6.337, 6.256, 6.131, 6.011, 5.953, 5.79 , 5.677, 5.609, 5.529, 5.441, 5.363, 5.33 , 5.218, 5.133, 5.047, 4.972, 4.893, 4.804, 4.68 , 4.559, 4.474], [23.403, 23.412, 23.412, 23.412, 23.412, 23.414, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan]], dtype=float32) - TEMP_QC(N_PROF, N_LEVELS)object...
- long_name :
- quality flag
- conventions :
- Argo reference table 2
array([[b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1'], [b'3', b'3', b'1', b'1', b'1', b'1', nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan]], dtype=object) - TEMP_ADJUSTED(N_PROF, N_LEVELS)float32...
- long_name :
- Sea temperature in-situ ITS-90 scale
- standard_name :
- sea_water_temperature
- units :
- degree_Celsius
- valid_min :
- -2.5
- valid_max :
- 40.0
- C_format :
- %9.3f
- FORTRAN_format :
- F9.3
- resolution :
- 0.001
array([[nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan], [nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan]], dtype=float32) - TEMP_ADJUSTED_QC(N_PROF, N_LEVELS)object...
- long_name :
- quality flag
- conventions :
- Argo reference table 2
array([[nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan], [nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan]], dtype=object) - TEMP_ADJUSTED_ERROR(N_PROF, N_LEVELS)float32...
- long_name :
- Contains the error on the adjusted values as determined by the delayed mode QC process
- units :
- degree_Celsius
- C_format :
- %9.3f
- FORTRAN_format :
- F9.3
- resolution :
- 0.001
array([[nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan], [nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan]], dtype=float32) - PSAL(N_PROF, N_LEVELS)float32...
- long_name :
- Practical salinity
- standard_name :
- sea_water_salinity
- units :
- psu
- valid_min :
- 2.0
- valid_max :
- 41.0
- C_format :
- %9.3f
- FORTRAN_format :
- F9.3
- resolution :
- 0.001
array([[36.697, 36.697, 36.697, 36.698, 36.698, 36.699, 36.706, 36.702, 36.558, 36.471, 36.437, 36.463, 36.493, 36.46 , 36.422, 36.414, 36.398, 36.343, 36.303, 36.272, 36.235, 36.206, 36.172, 36.128, 36.067, 35.986, 35.924, 35.859, 35.811, 35.771, 35.748, 35.722, 35.688, 35.662, 35.636, 35.6 , 35.577, 35.556, 35.532, 35.51 , 35.486, 35.465, 35.441, 35.429, 35.413, 35.402, 35.391, 35.386, 35.378, 35.361, 35.348, 35.346, 35.355, 35.377, 35.398, 35.414, 35.43 , 35.436, 35.442, 35.454, 35.47 , 35.495, 35.53 , 35.544, 35.533, 35.501, 35.476, 35.455, 35.435, 35.418, 35.411, 35.408, 35.387, 35.386, 35.379, 35.375, 35.363, 35.355, 35.341, 35.329, 35.324, 35.304, 35.29 , 35.283, 35.273, 35.262, 35.252, 35.248, 35.235, 35.225, 35.215, 35.206, 35.197, 35.186, 35.169, 35.153, 35.142], [36.701, 36.694, 36.695, 36.695, 36.697, 36.696, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan]], dtype=float32) - PSAL_QC(N_PROF, N_LEVELS)object...
- long_name :
- quality flag
- conventions :
- Argo reference table 2
array([[b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1', b'1'], [b'3', b'3', b'3', b'3', b'3', b'3', nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan]], dtype=object) - PSAL_ADJUSTED(N_PROF, N_LEVELS)float32...
- long_name :
- Practical salinity
- standard_name :
- sea_water_salinity
- units :
- psu
- valid_min :
- 2.0
- valid_max :
- 41.0
- C_format :
- %9.3f
- FORTRAN_format :
- F9.3
- resolution :
- 0.001
array([[nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan], [nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan]], dtype=float32) - PSAL_ADJUSTED_QC(N_PROF, N_LEVELS)object...
- long_name :
- quality flag
- conventions :
- Argo reference table 2
array([[nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan], [nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan]], dtype=object) - PSAL_ADJUSTED_ERROR(N_PROF, N_LEVELS)float32...
- long_name :
- Contains the error on the adjusted values as determined by the delayed mode QC process
- units :
- psu
- C_format :
- %9.3f
- FORTRAN_format :
- F9.3
- resolution :
- 0.001
array([[nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan], [nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan]], dtype=float32) - HISTORY_INSTITUTION(N_HISTORY, N_PROF)object...
- long_name :
- Institution which performed action
- conventions :
- Argo reference table 4
array([[b'IF ', b'IF '], [b'IF ', b'IF '], [b'IF ', b'IF ']], dtype=object) - HISTORY_STEP(N_HISTORY, N_PROF)object...
- long_name :
- Step in data processing
- conventions :
- Argo reference table 12
array([[b'ARFM', b'ARFM'], [b'ARGQ', b'ARGQ'], [b'ARGQ', b'ARGQ']], dtype=object) - HISTORY_SOFTWARE(N_HISTORY, N_PROF)object...
- long_name :
- Name of software which performed action
- conventions :
- Institution dependent
array([[b'CODA', b'CODA'], [b'COQC', b'COQC'], [b'COQC', b'COQC']], dtype=object) - HISTORY_SOFTWARE_RELEASE(N_HISTORY, N_PROF)object...
- long_name :
- Version/release of software which performed action
- conventions :
- Institution dependent
array([[b'027d', b'027d'], [b'3.8 ', b'3.8 '], [b'3.8 ', b'3.8 ']], dtype=object) - HISTORY_REFERENCE(N_HISTORY, N_PROF)object...
- long_name :
- Reference of database
- conventions :
- Institution dependent
array([[b' ', b' '], [b' ', b' '], [b' ', b' ']], dtype=object) - HISTORY_DATE(N_HISTORY, N_PROF)object...
- long_name :
- Date the history record was created
- conventions :
- YYYYMMDDHHMISS
array([[b'20190115112518', b'20190115112518'], [b'20190115112524', b'20190115112524'], [b'20190115112524', b'20190115112524']], dtype=object) - HISTORY_ACTION(N_HISTORY, N_PROF)object...
- long_name :
- Action performed on data
- conventions :
- Argo reference table 7
array([[b' ', b' '], [b'QCP$', b'QCP$'], [b'QCF$', b'QCF$']], dtype=object) - HISTORY_PARAMETER(N_HISTORY, N_PROF)object...
- long_name :
- Station parameter action is performed on
- conventions :
- Argo reference table 3
array([[b' ', b' '], [b' ', b' '], [b' ', b' ']], dtype=object) - HISTORY_START_PRES(N_HISTORY, N_PROF)float32...
- long_name :
- Start pressure action applied on
- units :
- decibar
array([[nan, nan], [nan, nan], [nan, nan]], dtype=float32) - HISTORY_STOP_PRES(N_HISTORY, N_PROF)float32...
- long_name :
- Stop pressure action applied on
- units :
- decibar
array([[nan, nan], [nan, nan], [nan, nan]], dtype=float32) - HISTORY_PREVIOUS_VALUE(N_HISTORY, N_PROF)float32...
- long_name :
- Parameter/Flag previous value before action
array([[nan, nan], [nan, nan], [nan, nan]], dtype=float32) - HISTORY_QCTEST(N_HISTORY, N_PROF)object...
- long_name :
- Documentation of tests performed, tests failed (in hex form)
- conventions :
- Write tests performed when ACTION=QCP$; tests failed when ACTION=QCF$
array([[b' ', b' '], [b'000000000008FB7E', b'0000000000689B7E'], [b'0000000000000000', b'0000000000600000']], dtype=object) - PARAMETER(N_PROF, N_CALIB, N_PARAM)object...
- long_name :
- List of parameters with calibration information
- conventions :
- Argo reference table 3
array([[[b'PRES ', b'TEMP ', b'PSAL ']], [[b'PRES ', b'TEMP ', b'PSAL ']]], dtype=object) - SCIENTIFIC_CALIB_EQUATION(N_PROF, N_CALIB, N_PARAM)object...
- long_name :
- Calibration equation for this parameter
array([[[b' ', b' ', b' ']], [[b' ', b' ', b' ']]], dtype=object) - SCIENTIFIC_CALIB_COEFFICIENT(N_PROF, N_CALIB, N_PARAM)object...
- long_name :
- Calibration coefficients for this equation
array([[[b' ', b' ', b' ']], [[b' ', b' ', b' ']]], dtype=object) - SCIENTIFIC_CALIB_COMMENT(N_PROF, N_CALIB, N_PARAM)object...
- long_name :
- Comment applying to this parameter calibration
array([[[b' ', b' ', b' ']], [[b' ', b' ', b' ']]], dtype=object) - SCIENTIFIC_CALIB_DATE(N_PROF, N_CALIB, N_PARAM)object...
- long_name :
- Date of calibration
- conventions :
- YYYYMMDDHHMISS
array([[[b' ', b' ', b' ']], [[b' ', b' ', b' ']]], dtype=object)
- title :
- Argo float vertical profile
- institution :
- CORIOLIS
- source :
- Argo float
- history :
- 2019-01-15T11:25:18Z creation; 2019-01-15T11:25:24Z last update (coriolis COQC software)
- references :
- http://www.argodatamgt.org/Documentation
- user_manual_version :
- 3.1
- Conventions :
- Argo-3.1 CF-1.6
- featureType :
- trajectoryProfile
- decoder_version :
- CODA_027d
This is an ideal occasion to remember one of the main properties of the netCDF format seen previously: It is a Self-Describing format.
The name for the core observations, temperature, salinity and pressure down to 2000 meters of depth, are TEMP, SALT and PRES. Although we could inspect the previous print-out of the cy1 dataset, we can use the data itself:
print(f"The core variables are: \n TEMP {cy1.TEMP.long_name} \n PSAL {cy1.PSAL.long_name} and \n PRES {cy1.PRES.long_name}")
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
<ipython-input-1-dcf936167f67> in <module>
----> 1 print(f"The core variables are: \n TEMP {cy1.TEMP.long_name} \n PSAL {cy1.PSAL.long_name} and \n PRES {cy1.PRES.long_name}")
NameError: name 'cy1' is not defined
In this file, the variables TEMP_ADJUSTED, PSAL_ADJUSTED and PRES_ADJUSTED are also shown, which correspond to data that has gone through the second stage of quality control. However, here we keep the focus on the Real-Time data in section Real-Time and Delayed mode data.
print(f"The dimesions of TEMP are:\n {cy1.TEMP.dims[0]}:{cy1.TEMP.shape[0]} \n {cy1.TEMP.dims[1]}:{cy1.TEMP.shape[1]}")
The dimesions of TEMP are:
N_PROF:2
N_LEVELS:97
We note that for for the first cycle there are two profiles (N_PROF=2) and 97 vertical levels… lets plot them:
fig, ax = plt.subplots(1,2,figsize=(8,10))
#Temperature
ax[0].plot(cy1.TEMP[0],-cy1.PRES[0],'b-',label='N_PROF=0')
ax[0].plot(cy1.TEMP[1],-cy1.PRES[1],'r.',label='N_PROF=1')
ax[0].set_title(cy1.TEMP.long_name)
ax[0].set_ylabel(cy1.PRES.long_name)
ax[0].grid()
ax[0].legend()
#Salinity
ax[1].plot(cy1.PSAL[0],-cy1.PRES[0],'b-',label='N_PROF=0')
ax[1].plot(cy1.PSAL[1],-cy1.PRES[1],'ro',label='N_PROF=1')
ax[1].set_title(cy1.PSAL.long_name)
ax[1].grid()
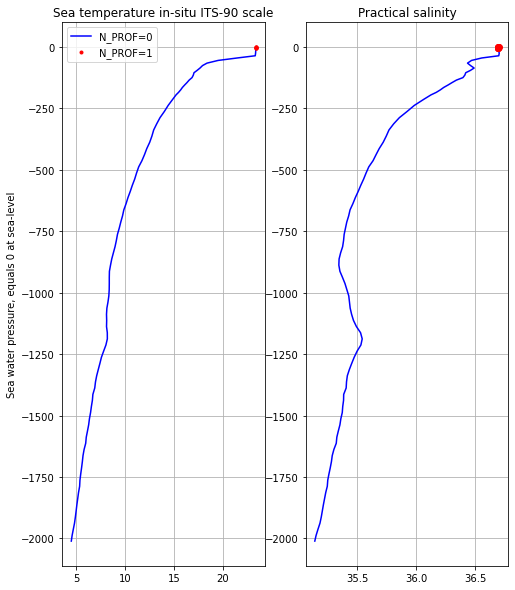
This is, within the cycle file, there are two profiles. The first one (N_PROF=0 in blue) is measured during its ascend from 2000 dbar to 5 dbar and it constitutes the core Argo program; the second one (N_PROF=1 in red) only measures the top 5 dbar.
Once again all the information is in the netcf file, the data variable VERTICAL_SAMPLING_SCHEME contains all the details:
print(f"The first profile is the: { str(cy1.VERTICAL_SAMPLING_SCHEME[0].astype(str).values) }")
The first profile is the: Primary sampling: averaged [10 sec sampling, 25 dbar average from 2000 dbar to 200 dbar; 10 sec sampling, 10 dbar average from 200 dbar to 10 dbar; 10 sec sampling, 1 dbar average from 10 dbar to 5.5 dbar]
print(f"The second profile is the: {cy1.VERTICAL_SAMPLING_SCHEME[1].astype(str).values}")
The second profile is the: Near-surface sampling: averaged, unpumped [10 sec sampling, 1 dbar average from 5.5 dbar to surface]
Ago floats may measure several profiles in each cycle, however, as a rule of thumb the first profile is always the core mission Argo CTD profile (2000 dbar - 5 dbar). In the case of this float there is an additional second profile, with higher resolution (10 sec sampling and 1 dbar average) but unpumped. The sensor of conductivity (for salinity) doesn’t pump water through to avoid contamination or biodeposition from the surface. The data from this second profile is used, mostly, for calibrations of SST observations from satellites.
In the Reference table 16: vertical sampling schemes of the Argo Data Management Team. Argo user’s manual. https://doi.org/10.13155/29825 there is a description of all the different options in VERTICAL_SAMPLING_SCHEME. However, a discussion of all of them is beyond the objective of this AoS than focusing on understanding the basic concepts.
The descending profile#
As mentioned before, some floats also make measurements in the first descending phase of the first cycle. The data is in the <R/D>
cy1D = xr.open_dataset('../../Data/6901254/profiles/R6901254_001D.nc')
print(f"The dimesions of TEMP are:\n {cy1D.TEMP.dims[0]}:{cy1D.TEMP.shape[0]} \n {cy1D.TEMP.dims[1]}:{cy1D.TEMP.shape[1]}")
The dimesions of TEMP are:
N_PROF:1
N_LEVELS:51
in this case there is only one profile, let’s plot it together with the ascending data (cy1):
fig, ax = plt.subplots(1,2,figsize=(8,10))
#Temperature
ax[0].plot(cy1D.TEMP[0],-cy1D.PRES[0],'k-',label='N_PROF=0 Descending',linewidth=3.0)
ax[0].plot(cy1.TEMP[0],-cy1.PRES[0],'b-',label='N_PROF=0 Ascending')
ax[0].plot(cy1.TEMP[1],-cy1.PRES[1],'ro',label='N_PROF=1 Ascending')
ax[0].set_title(cy1.TEMP.long_name)
ax[0].set_ylabel(cy1.PRES.long_name)
ax[0].grid()
ax[0].legend()
#Salinity
ax[1].plot(cy1D.PSAL[0],-cy1D.PRES[0],'k-',label='N_PROF=0 Descending',linewidth=3.0)
ax[1].plot(cy1.PSAL[0],-cy1.PRES[0],'b-',label='N_PROF=0 Ascending')
ax[1].plot(cy1.PSAL[1],-cy1.PRES[1],'ro',label='N_PROF=1 Ascending')
ax[1].set_title(cy1.PSAL.long_name)
ax[1].grid()
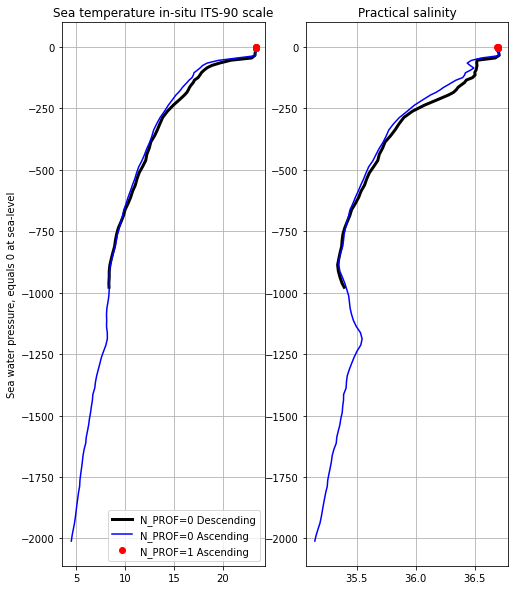
As indicated in the figure, the first descending is only until the parking depth.
Geographical information#
The NetCDF file includes information about the geographical position of the observations (LONGITUDE and LATITUDE) and the date of the observation (JULD).
for variable in ['LONGITUDE', 'LATITUDE' , 'JULD']:
print(f"The {cy1.data_vars[variable].long_name} is in the variable {variable}")
The Longitude of the station, best estimate is in the variable LONGITUDE
The Latitude of the station, best estimate is in the variable LATITUDE
The Julian day (UTC) of the station relative to REFERENCE_DATE_TIME is in the variable JULD
Let’s plot it
fig, ax = plt.subplots(figsize=(8,8))
ax.plot(cy1D.LONGITUDE[0],cy1D.LATITUDE[0],'ko',label='001D N_PROF=0 Descending')
ax.plot(cy1.LONGITUDE[0],cy1.LATITUDE[0],'bo',label='001 N_PROF=0 Ascending')
#ax.set_title(cy1..long_name)
ax.set_xlabel(cy1.LONGITUDE.long_name)
ax.set_ylabel(cy1.LATITUDE.long_name)
ax.text(cy1D.LONGITUDE[0],cy1D.LATITUDE[0],'Date of observation for 001D:'+cy1D.JULD[0].values.astype(str), fontsize=14)
ax.text(cy1.LONGITUDE[0],cy1.LATITUDE[0],'Date of observation for 001:'+cy1.JULD[0].values.astype(str), fontsize=14)
ax.grid()
ax.legend();
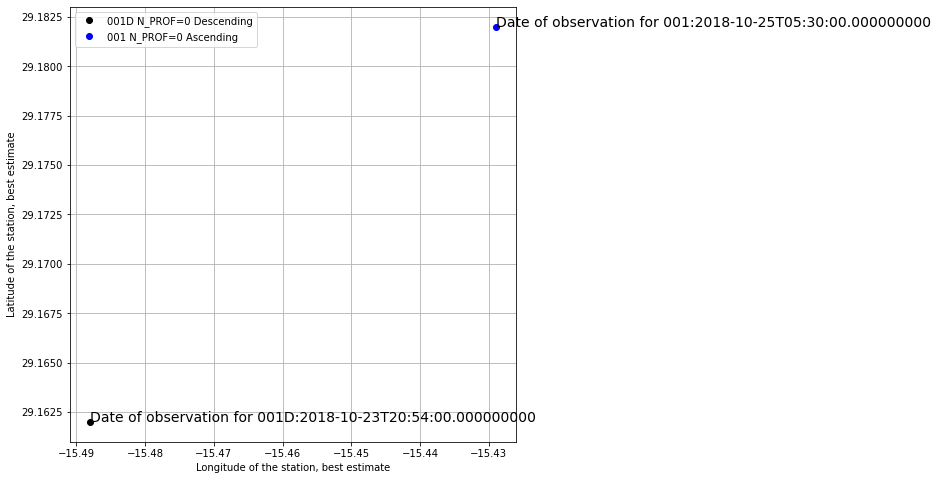
The 2 ascending profiles in 001 have, obviously, the same time stamp:
print(cy1.JULD[0].values.astype(str))
print(cy1.JULD[1].values.astype(str))
2018-10-25T05:30:00.000000000
2018-10-25T05:30:00.000000000
Note that for some floats there is a <R/D>
Meta information in the cycle file#
The NetCDF file for each cycle includes a lot of additional information about each one of the profiles in it. Let’s take a look at the basic information.
print(f"For cycle {cy1D.CYCLE_NUMBER.astype(int).values} The {cy1D.DIRECTION.long_name} (DIRECTION) is {cy1D.DIRECTION.values.astype(str)}")
print(f"For cycle {cy1.CYCLE_NUMBER.astype(int).values} the {cy1.DIRECTION.long_name} (DIRECTION) is {cy1.DIRECTION.values.astype(str)}")
For cycle [1] The Direction of the station profiles (DIRECTION) is ['D']
For cycle [1 1] the Direction of the station profiles (DIRECTION) is ['A' 'A']
A is for ascending and D for descending.
And all the meta information of the float, and for each profile within each cycle, among others:
for variable in ['PLATFORM_NUMBER','DATA_CENTRE','PROJECT_NAME','PI_NAME']:
print(f"The {cy1.data_vars[variable].long_name} ({variable}) is {cy1.data_vars[variable].values.astype(str)}")
The Float unique identifier (PLATFORM_NUMBER) is ['6901254 ' '6901254 ']
The Data centre in charge of float data processing (DATA_CENTRE) is ['IF' 'IF']
The Name of the project (PROJECT_NAME) is ['ARGO SPAIN '
'ARGO SPAIN ']
The Name of the principal investigator (PI_NAME) is ['Pedro Velez '
'Pedro Velez ']
We can also access the dimession that define the profile
for key in cy1.dims.keys():
print(key,cy1.dims[key])
N_PROF 2
N_PARAM 3
N_LEVELS 97
N_HISTORY 3
N_CALIB 1
N_LEVELS is the number of vertical leves, i.e. in pressure. N_PROF the number of profiles within the cycle, as we saw previously. N_PARAM is te number of paramters, 3 for this float: TEMP, PSAL and PRES
Later we will explain N_CALIB and N_HISTORY
Meta data#
There is a lot of additional meta information in the <FloatWmoID>_meta.nc file
Mdata = xr.open_dataset('../../Data/6901254/6901254_meta.nc')
Always, basic information appears in all the netcdf files of an Argo float:
for variable in ['PLATFORM_NUMBER','DATA_CENTRE','PROJECT_NAME','PI_NAME']:
print(f"The {Mdata.data_vars[variable].long_name} ({variable}) is {Mdata.data_vars[variable].values.astype(str)}")
The Float unique identifier (PLATFORM_NUMBER) is 6901254
The Data centre in charge of float real-time processing (DATA_CENTRE) is IF
The Program under which the float was deployed (PROJECT_NAME) is ARGO SPAIN
The Name of the principal investigator (PI_NAME) is Pedro Velez
and some examples of additional information.
for variable in ['FIRMWARE_VERSION','BATTERY_TYPE','DEPLOYMENT_PLATFORM','CONFIG_PARAMETER_NAME','SENSOR_SERIAL_NO']:
print(f"The {Mdata.data_vars[variable].long_name} ({variable}) is {Mdata.data_vars[variable].values.astype(str)}")
The Firmware version for the float (FIRMWARE_VERSION) is n/a
The Type of battery packs in the float (BATTERY_TYPE) is LITHIUM
The Identifier of the deployment platform (DEPLOYMENT_PLATFORM) is ANGELES ALVARI?O
The Name of configuration parameter (CONFIG_PARAMETER_NAME) is ['CONFIG_CycleTime_hours '
'CONFIG_ParkPressure_dbar '
'CONFIG_ProfilePressure_dbar '
'CONFIG_DescentToParkPresSamplingTime_seconds '
'CONFIG_Direction_NUMBER ']
The Serial number of the sensor (SENSOR_SERIAL_NO) is ['n/a ' 'n/a ' 'n/a ']
The full descritpion of variables is in the Argo user’s Manual